Docs
Python SDK
The Python SDK enables Python developers to speed up and ease the integration with Blockbax. It makes interfacing with our HTTP API even easier where you can easily get, create, update and delete resources without the intricacies of having to deal with HTTP requests and responses.
Features
The Python SDK handles client configuration, API token handling, resource interfacing, logging and error handling to access the Blockbax Platform APIs.
Client configuration
Configuring an HTTP Client takes only one function call and can be configured using only the project ID and an access key.
| |
API token handling
The HTTP Client provides an automatic authorization mechanism based on the provided access key.
Resource interfacing
Resources can be manipulated using Python dataclasses with proper type hinting to reduce avoidable errors.
| |
Logging
The Python SDK uses the built-in logging module. Logging can be enabled or disabled and set to the required level.
Error handling
The Python SDK provides an error handling mechanism. Different error classes help to identify whether an error was caused by the HTTP Client or the Blockbax server. Detailed information such as HTTP status, error details and error message from the service are included in these error classes.
Throttling requests
The Blockbax Platform uses rate limits to avoid resource starvation. The Python SDK handles rate limits automatically by throttling the underlying requests.
Retry mechanism
Due to the distributed nature of the Blockbax Platform, the HTTP API requests can incidentally give certain error responses which can safely be retried. The Python SDK has a retry mechanism that automatically retries these errors using an exponential back-off mechanism.
Use cases
The Python SDK can be used in a large variety of use cases. Whether you want to automatically manage your resources or perform complex data analysis our SDK will empower these various use cases.
Data science
You can use the SDK to apply data science techniques like machine learning to unravel hidden patterns. The SDK integrates seamlessly with your favorite tools. For example because all Blockbax resources are presented as dataclasses resources from Blockbax can easily be converted to a pandas DataFrames. This makes interacting with resources from Blockbax even easier by combining the built-in functionalities of pandas with the SDK.
See below a simple example of how to use the SDK in combination with a Jupyter Notebook:
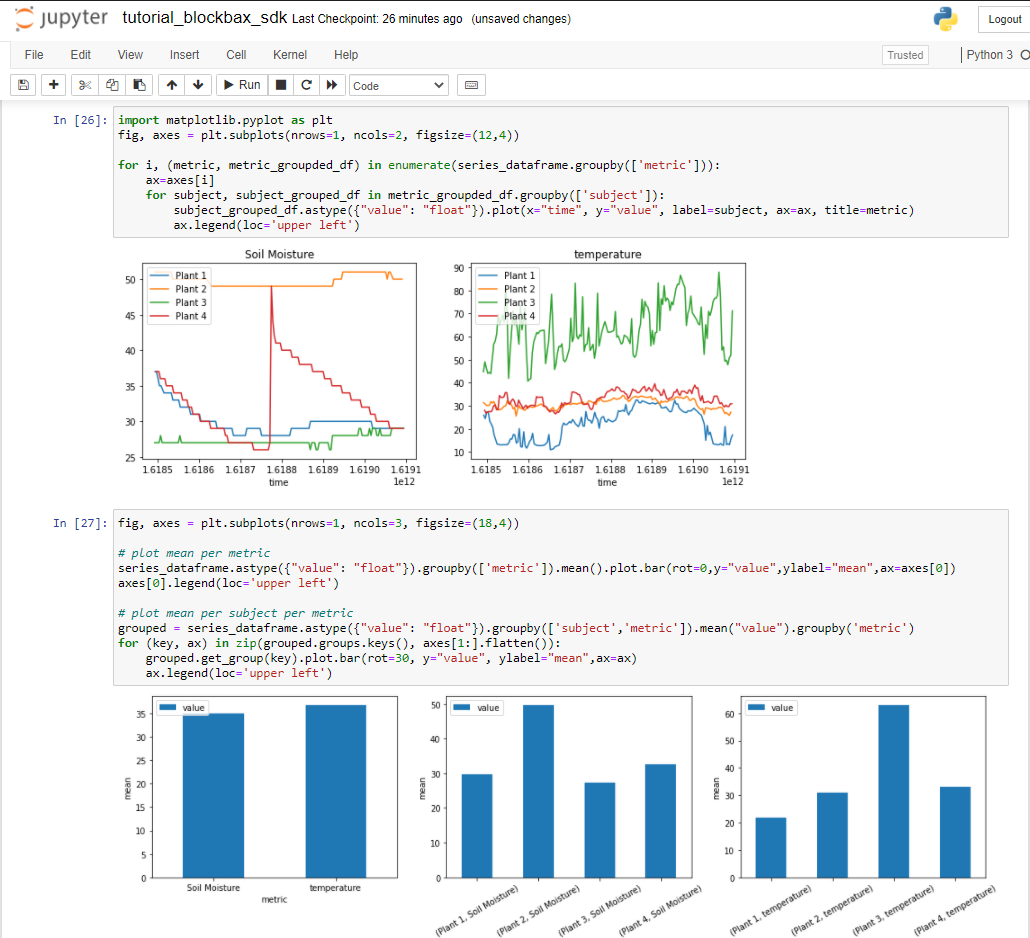
Sending measurements
With the Python SDK sending data to the Blockbax Platform can be done in just two steps.
Queuing
To queue a new measurement all you need to know is the ingestion ID, a time and the value of the measurement to queue. There are two possible measurements that you can queue, a numeric measurement and a location measurement.
Sending
Sending measurements is as easy as calling one function. You do have some extra options to chose from. If you want to send only measurements for a specific set of ingestion IDs you can optionally provide a list of ingestion IDs. Another option is to automatically create subjects. You can enable this feature when you want to automatically create subjects when it does not exist yet.
Data synchronization
One of the most powerful aspects of the Python SDK is the way it handles Blockbax resources. This makes it perfect for instance to synchronize meta-data with your own systems of record or forward measurements and events to your data lake. By changing attributes of dataclasses or using the built-in methods developers are not required to keep track of every detail and can write update mechanisms without the need to write complicated code.