October 23, 2024 · 12 min read
Forecasting water quality using AI

Recently we released our latest feature called forecasted metrics as a private beta to test with a select group of customers. It is a pioneering feature which adds AI capabilities to the Blockbax Platform. A forecasted metric allows you to forecast future values of an existing metric.
In this blog we do a deep-dive using a specific forecasting case of our customer Additive Catchments, which we hope you can draw inspiration from for your own use cases. Additive Catchments is a UK-based organization dedicated to improving water management and environmental stewardship through innovative technology. Their main purpose is to enhance the health of water catchments (areas where water is collected by the natural landscape) by offering comprehensive monitoring and management services.

“Leveraging the AI capability within Blockbax has enabled us to rapidly iterate and build robust forecasting models with high confidence and governance, seamlessly integrated in the same user-friendly environment. This has led to intuitive and actionable insights we can directly use in our existing monitoring setup.”
Approach
For this case we adopted a typical methodology to approach an AI project. We began by defining the goal and worked in several steps towards developing and deploying the forecasting model. We will generally introduce each step and then describe the details specific to this case, so that it can serve as a guide for other projects as well.

1. Problem (or goal) definition
Water companies have to act on water quality since all rivers in the UK need to be monitored by 2035 according to Section 82 of the Environment Act 2021. This act addresses the pressing issue of water pollution from storm overflows, which occur when heavy rainfall overwhelms sewer systems. This results in untreated sewage to be discharged into rivers, lakes, and coastal waters causing significant environmental and public health impacts. Additive Catchments wants to not only find a way to measure and monitor to comply on legislation, they want to take it one step further and forecast possible river pollution. Hence the goal is defined as:
Forecast the water quality for better management, regulatory enforcement and public awareness, ultimately leading to cleaner waterways and enhanced environmental protection.
2. Data collection and preparation
For existing users, like Additive Catchments, data collection and preparation (i.e. cleaning) is not necessary anymore. All contextual data is there and measurement readings are continuously being ingested into the Blockbax Platform. All this data can be used to train a forecasting model on and later make live forecasts on incoming data without any additional steps. In case new data is required this can easily be added using our off the shelf connectors or by creating a custom one.
Typically this is the most time-consuming (and least glamorous) part of an AI project, however in a typical setup the platform takes care of the format and consistency of the data. Next to that it takes care of duplicate values, filters unwanted outliers and reformats data types.
In short: Configure the platform and you are good to go!
3. Data exploration
In this step you want to get a deeper understanding of the data by working closely with domain experts, typically making various data visualizations and cross-checking uncovered statistical characteristics. In this case the customer’s domain experts mentioned that dissolved oxygen (DO) is important to forecast since it will tell a lot about the water quality. There is also a theoretical basis that water temperature is a primary factor in influencing DO levels. Cooler water can hold more DO, while warmer water holds less.
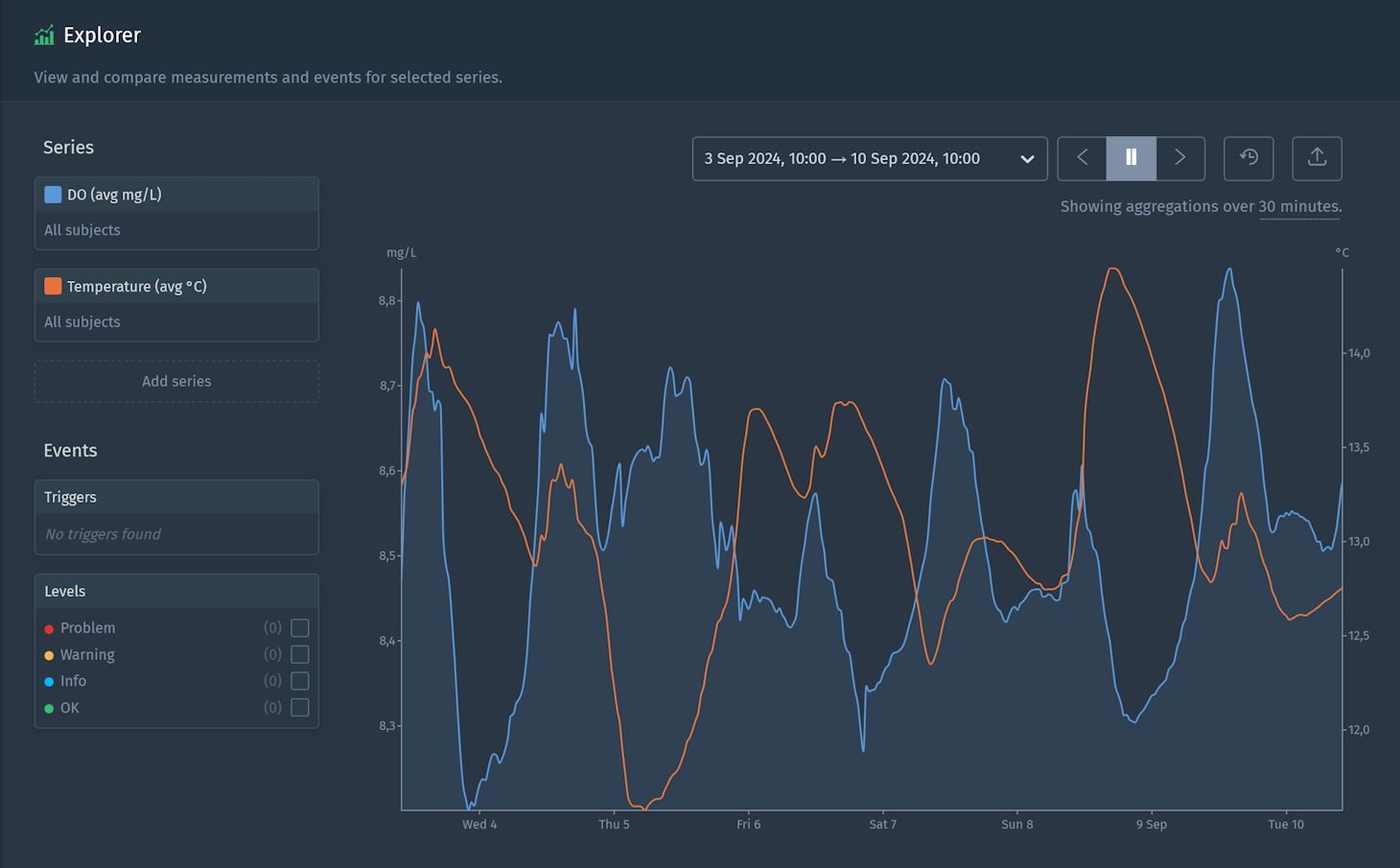
To prove the point that temperature fluctuations directly impact DO concentrations, we visually inspected the data using the Explorer in Blockbax (see image below) and did a statistical analysis. We found a strong consistent negative correlation between the DO and water temperature, indicating that as water temperature increases, DO levels tend to decrease. This confirmed our theory with data from the real measurements.
4. Model development, training, evaluation and refinement
This step involves developing the AI model aimed at solving the defined problem and train it using relevant data. This step is iterative, often involving multiple rounds of model development and refinement based on the model’s performance during training. In general, the steps in the approach are not necessarily linear. In this step you might also get ideas about which additional data could be beneficial to make an accurate forecast.
Traditionally, developing a model is where a data scientist gets to work and uses code to train various models using AI/ML libraries. We abstracted away from code to allow everyone to do this. Still, very specific use cases might require specialized models which can be integrated using our API. Your data scientists might also want to take on the challenge of beating the Blockbax’s forecast - we are open for challenge. 😉
No code is required when using the forecasted metrics feature of Blockbax. You can easily set it up with a little bit of configuration. You select the metric you want to forecast and how far into the future this should be.
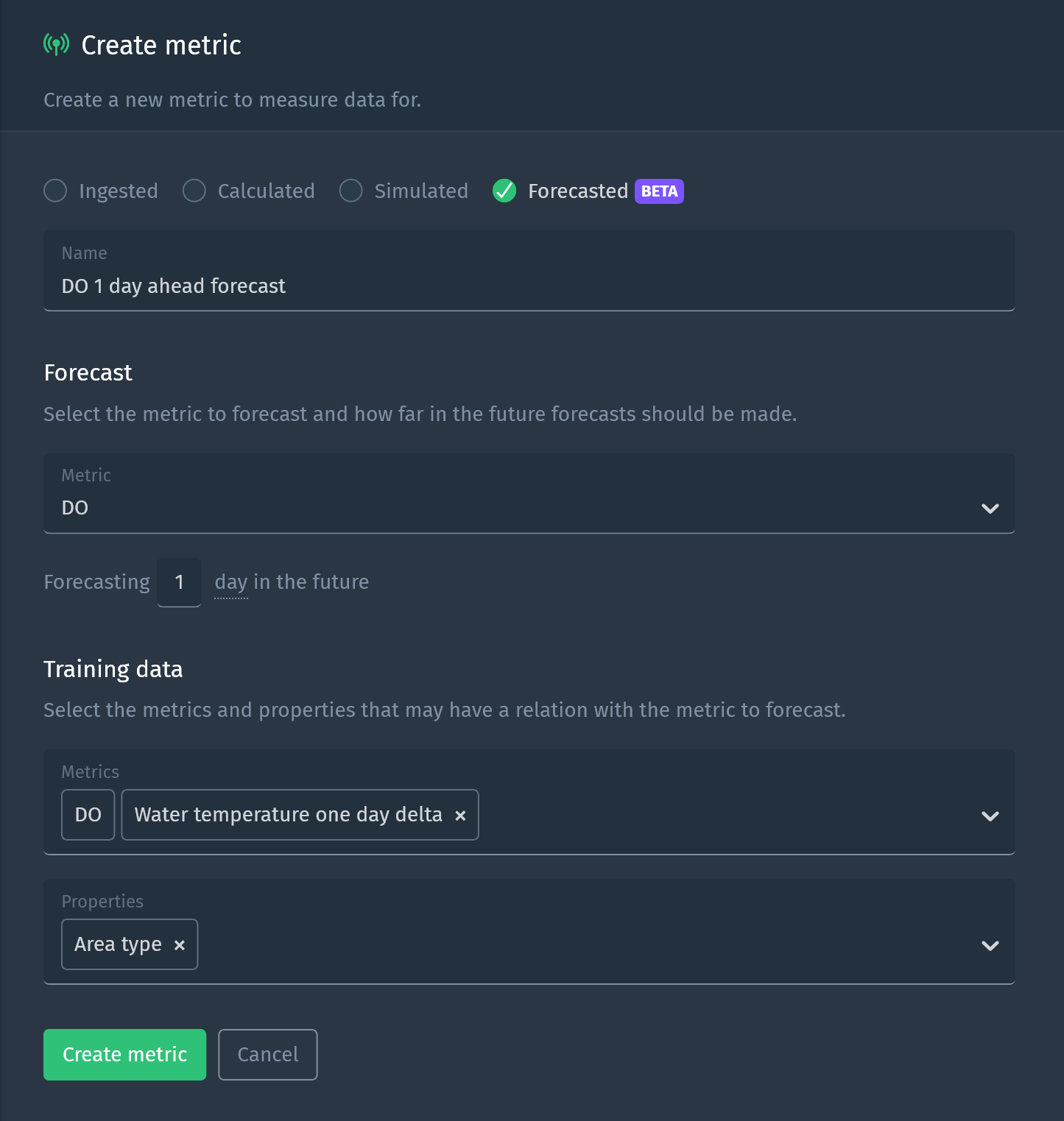
Additionally, we select which other metrics and properties we think are relevant to use as training data. We then evaluate the model’s performance by looking at how accurate it can forecast. By experimenting with different training configuration we are able to refine the model and get the best performance. The platform will only accept models if they result in improved performance.

The part of developing a model which is often overlooked while being vital to success is called feature engineering. Feature engineering is the process of transforming existing data into data to serve as model input during training and deployment. In almost all cases the algorithms used in AI are standard and provided by a small set of underlying libraries, this makes feature engineering the part that can make or break your AI project.
To make data more useful for a model, it can be beneficial to not just add the existing metrics to the training data, but construct new metrics to make them more useful for the model. For example, to use the rate of increase or decrease as a feature instead of simply the value of a metric. We could also engineer features based on the date and time, like whether it is day or night or a working day or not. In Blockbax these features can easily be engineered using calculated metrics.
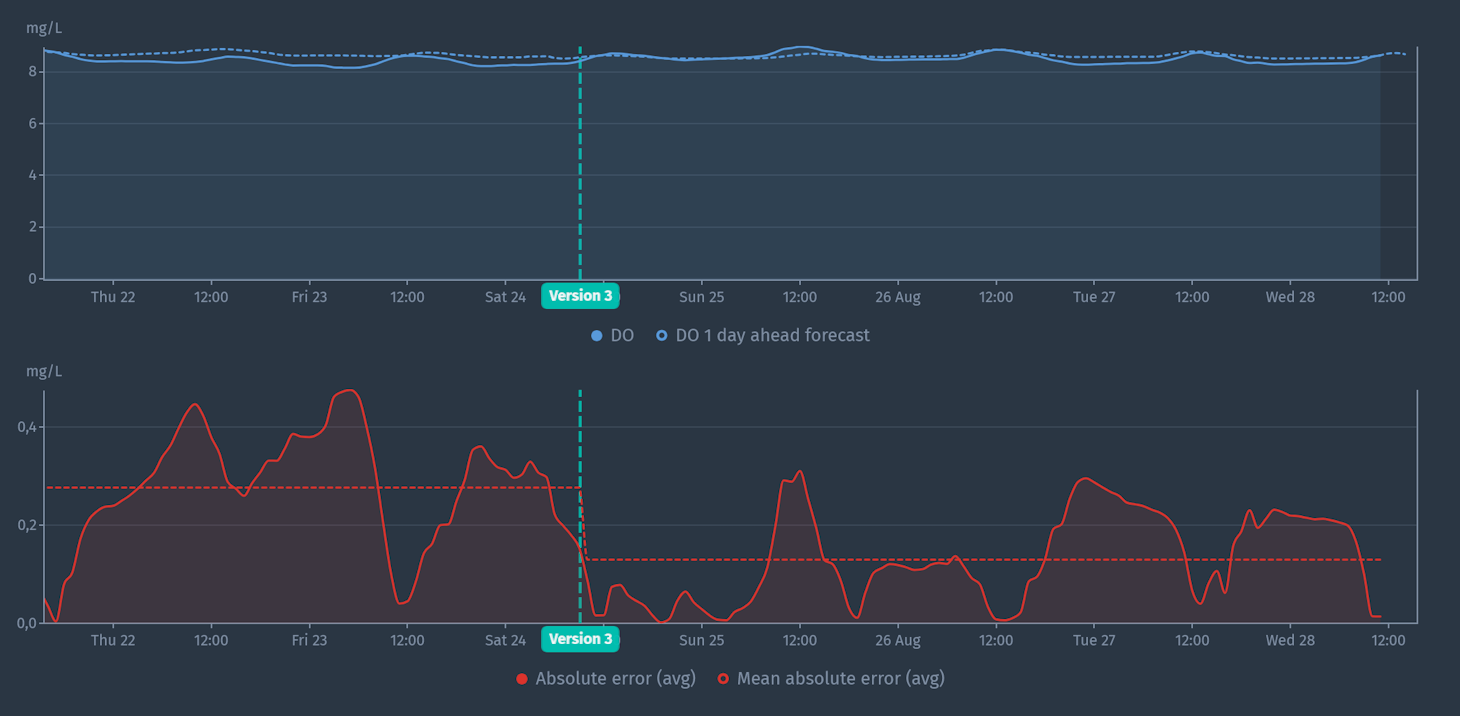
We made many iterations in our project to create a forecasting model for DO. In line with the data exploration, we figured that when water temperature is expected to greatly influence DO, we should first aim to forecast water temperature and use this forecast as training data. Water temperature is greatly influenced by the air temperature and rain. Forecast data for these are readily available via weather forecast services, which we can make available using ingested metrics. This data we used to train a separate forecasted metric for water temperature, which we got really accurate. Finally, adding the water temperature forecast to our training data to forecast DO was one of the major breakthroughs to get to an accurate forecast. Our final model was able to forecast one day ahead quite accurately with a mean absolute error (MAE) of 0.13 mg/L.

5. Deployment
Once the model is performing satisfactorily, it can start solving real-world problems. Typically this would involve a hand-over between a data scientist and a data engineer which would deploy the model to a production environment and integrate it with existing systems. In Blockbax, deploying is a matter of pressing the save button and forecasts fully integrate with existing functionality - meaning you can do everything with a forecast like you would with any other metric.
Here are some use cases which are made possible by combining forecasts with existing functionality:
- Trigger a rule-based event once the DO is forecasted to decrease significantly
- Make a notification for this event and/or create an alarm for an operator to act upon
- Take automated action
6. Operations and maintenance
After deployment, the model needs to be maintained and updated. You want to monitor the model’s performance to ensure it’s still working as expected, update the model with new data, or refine the model based on feedback from domain experts. For monitoring performance you can look at how the accuracy (i.e. MAE) is evolving (see image below). If the accuracy is decreasing you probably want to look into it and try if an updated model can improve it. By default, the platform retrains a model automatically every two months to make sure new observations are automatically taken into account.
Conclusion
It is possible to accurately forecast water quality by utilizing Blockbax Platform functionality. Additive Catchments will use these forecasts for better management, regulatory enforcement and public awareness, ultimately leading to cleaner waterways and enhanced environmental protection.
Zooming out we can sum up the main differentiators of a traditional approach compared to the Blockbax approach as follows:
| Stage | Traditional approach | Blockbax approach |
|---|---|---|
| Data collection, preparation and exploration | Manual data manipulation and analysis, most time-consuming (and least glamorous) part. | Beating heart of the Blockbax platform - users setup a project like any other and they are good to go! |
| Model development, training, evaluation and refinement | A data scientist gets to work and uses code to develop a model and iterate. | Abstracted away from code into a UI to allow everyone to do this and iterate faster. |
| Deployment | A data engineer prepares the infrastructure and deploys the model for other software developers to build upon. | Just works without extra infrastructure, and integrates with all existing functionality like alarms and automation. |
| Operations and maintenance | A data scientist maintains the model and a data engineer maintains the infrastructure manually. | About zero to none, automatic retraining and -deployment happens periodically or can be initiated with one click. |
In short, the Blockbax platform supports you in every step of developing and deploying a forecasting model. It now only takes a few clicks instead of a lot of development time from specialized data scientists and engineers.
What’s next?
We believe this feature is ready to make an impact! We will be developing it further in private beta with a select group of customers. If you are interested or have any questions, please don’t hesitate to contact us.
Cheers,
The Blockbax Team.


